As an example, consider the Kerr-Newman Metric. It can be parameterized as
gr r = -f / (2 h r)withgθ θ = -f / q
gφ φ = -a4 q / f + 2 a2 h q2 r / f -
2 a2 q r2 / f - q r4 / fgφ t = a e2 q / f - 2 a M q r / fgt t = -a2 c2 / f - e2 / f + 2 M r / f - r2 / f
f = a2 c2 + r2By reducing the class of problems of interest to those that can be represented as polynomials with real coefficients and integer exponents, weh = (a2 + e2 + r (-2 M + r)) / (-2 r)
q = c2 - 1
1 / ( 1 + k / r3 ) ( 1 / n ) = 1 / q ->so that, for instance,qn = 1 + k / r3
n q ( n - 1 ) dq / dr = - 3 k / r4and
dq / dr = - 3 k / ( n q( n - 1 ) r4 )
u'(r) = v(r) andOnly two derivatives are needed as long as any computations only involve the Christoffel Symbols and the various curvature tensors.u''(r) = w(r)
Sanity checks are an important part of any algorithm, especially one as general as we are attempting:
#ifdef debugto allow some sanity checking to be easily turned off when the application is "stable".
(index value) << (4 * index number) + ((value < 0) ? 1 << 50 : 0) in long longs.
((spinor index) ? (index value) << (4 * number of spacetime indices + 8 * spinor index number) :(index value) << (4 * spacetime index number)) +((value < 0) ? 1 << 50 : 0) + ((value = +- I) ? 1 << 51 : 0)
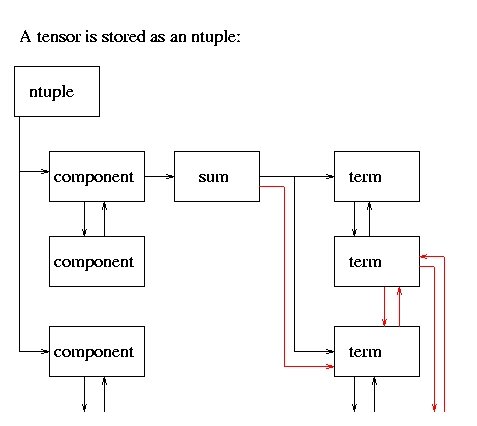
term contains
a long long coefficient andterm is a subclass of element, which are linked into hash lists (see below).an array of integer exponents, one for each coordinate, parameterization function, ansatz, constant and fraction denominator (like halves, thirds, etc.).
Before adding terms, one must be sure that all powers, including those of fractions, are identical, andbefore storing terms, one must cancel common factors of fractions with the coefficient (ie., 6 * 2-1 should be replaced by 3 * 20).
A sum is a linked list of terms, each with a unique set of exponents. (ie.,
2 r3 a + 3 r3 a should be stored as 5 r3 a).
The list is actually split into an array of lists, and the exponents are hashed to select a
particular list in the array on which to store any given term. During the development of PTAH, we chanced upon
a novel hash algorithm which reduced collision frequency by O(10):
for (int i = 0; i < rank; i++) {
product = (product | last_hash) - (product & last_hash);}
sum is a subclass of hash, where all operations involving linked list traversal, insertion and
removal are collected.
Simplification of sums requires a little work. For instance,
( r4 + 2 a2 r2 +
a4 ) / p3 -> 1 / p
Simplification has not proven very easy or effective, and is not used on scalar invariants during
parallel runs because output is currently only collected at the end.
The sum class contains methods to
zero, assign, search for, add and multiply sums, and to
take partial derivatives, simplify and output sums.
inline void hash_code (int* factor_powers_param) {
The hash size is in general a prime number (PTAH currently uses 293). Of course, when a collision occurs
(two terms hashing into the same list), the list is searched linearly.
long product = size;
last_hash = factor_powers_param[i] * (i + 1) * ((int) variables[i]);
last_hash = labs (product) % size; }
if p = r2 + a2, we would like
We have found that polynomial division is most effective when simplifying from high to low
values of the exponents, so:
The red arrows indicate the links for the sort lists used during simplification.
Here is a partial
comparison of PTAH timings with Mathematica for the
above analyses of KerrD (times are in seconds):
* = does not include computation of the Euler Class
due to the excessive time required
©2005, Kenneth R. Koehler. All Rights Reserved. This document may be freely reproduced provided that this copyright notice is included.
Please send comments or suggestions to the author.
PVM - Parallel Virtual Machine
PVM is the underlying
MIMD cluster
software chosen for PTAH. It was chosen primarily because it provides tools to build in
fault tolerance. PVM provides procedures for
interrogating the cluster configuration,
spawning tasks,
sending and receiving messages (both data and control) between tasks and
providing notification when a task dies.
PVM does not guarantee message ordering, so that must be done by hand.
Hybridization with Mathematica
PTAH provides Mathematica functions to write C++ header files for the
exportation of tensors and parameters.
C++ procedures in PTAH then build sums and ntuples from the information in the header files.
PTAH output is formatted as Mathematica FullForm, providing
easy importation into Mathematica for further analysis.
PTAH also
outputs the definition of a simplification function to replace parameterization functions by their definitions.
These computations were performed on one 1533 MHz Athlon with 512 MB of DDR-266 RAM.
D Mathematica PTAH number of products computed by PTAH
maximum PTAH working set (MB) 4 35 6 87328 7 5 89 17 119715 11 6 785 21 185787 18 7 1524 52 239144 28 8 5086* 106 336566 44 9 14348 309 427735 67 10 39482* 13323 827700 99 11 95367 3117 723598 142